二十八、正则术语
正则表达式是由普通字符和特殊字符组成
普通字符:字母、数字
特殊字符:具有特殊含义的字符() [] {} + ? * .
如果相匹配特殊字符,需要添加转义:\
28.1 精确匹配
只匹配普通字符就是精确匹配
1 | // 精确匹配只含有普通字符 |

28.2 特殊预定义字符
1 | \t :制表符 |
28.3 字符集
1 | [] :表示字符集,用于字符可能性匹配 |
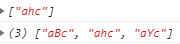
28.3.1 简单字符集 [abc]
简单字符集:将所有的可能性直接书写在中括号内部,一次中括号只能匹配一个结果
1 | var str = "abcncjahckajayck"; |

28.3.2 范围类 [0-9]
范围类:将同种数据书写在一起,用-连接。比如[0-9] [a-z]
1 | // 范围类:使用 - 连接 |

28.3.3 组合类 [0-9a-z]
组合类:不同范围匹配。比如[0-9a-z]
1 | // 组合类 |

28.3.4 负向类 [^0-9]
负向类:表示不含有这些可能性 用 [^] 表示,紧挨着左中括号书写在后面
1 | // 负向类 |

28.4 修饰符
正则表达式可以在//后面书写修饰符
28.4.1 //g 全局匹配
g:表示全局匹配,当匹配到第一个满足条件的字符串不会停止,继续匹配所有满足条件的字符串。
1 | var str = "abcncjahckajayck"; |

28.4.2 //i 对大小写不敏感
i :js严格区分大小写,如果书写i表示对大小写不敏感
修饰符可以书写多个
1 | // i 表示对大小写不敏感 |
28.5 量词
用于处理紧密相连的多个同类的字符
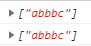
28.5.1 {n}:硬性量词
{n}:硬性量词。表示该字符连续出现n次。
1 | var str = "abbbcabbbbbc"; |
28.5.2 {n,m} :软性量词
{n,m} :软性量词。表示字符连续出现至少n次,最多不能超过m次
28.5.3 {n,} :至少出现n次,最多没有限制
{n,} :至少出现n次,最多没有限制
1 | var str = "abbbcabbbbbcabbbbbbbbbbbbbbbc"; |

28.5.4 + :表示至少出现1次
+ :表示至少出现1次。等价于 {1,}
1 | var str = "acabcabbbcabbbbbcabbbbbbbbbbbbbbbc"; |

28.5.5 ? :表示出现 0 或 1 次
? :表示出现 0 或 1 次 等价于 {0,1}
1 | var str = "acabcabbbcabbbbbcabbbbbbbbbbbbbbbc"; |
28.5.6 *:表示出现任意次
*:表示出现任意次 等价于{0,}
1 | var str = "acabcabbbcabbbbbcabbbbbbbbbbbbbbbc"; |
28.6 边界
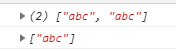
28.6.1 ^ 开头匹配
^ :书写在正则表达式最左侧,表示开头匹配。表示能够匹配^后面所有字符作为开头。
1 | var str = "abciabc"; |
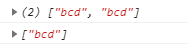
28.6.2 $ 结尾匹配
$:结尾匹配,书写在正则表达式最右侧。表示以$前面所有的字符作为结尾匹配。
1 | var str = "abbcdciabcd"; |
28.6.3 ^$案例
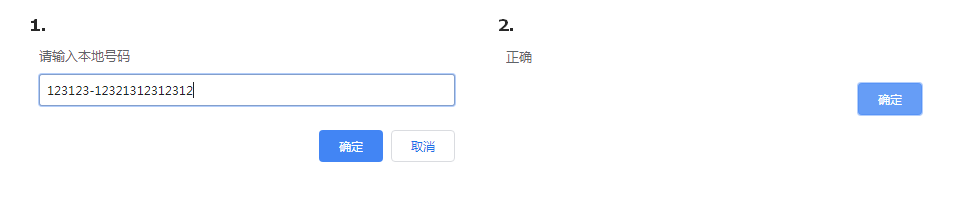
① 不加边界 字数超了仍显示正确
1 | // 验证号码正确性 000-1234567 没有其他字符 |
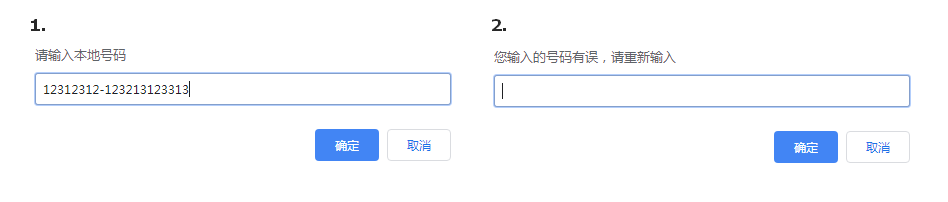
② 添加边界
1 | // 验证号码正确性 000-1234567 没有其他字符 |
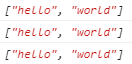
28.6.4 \b 单词边界
\b :表示单词边界。匹配位于单词开头或者结尾字符
1 | var str = "hello world"; |
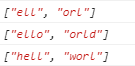
28.6.5 \B 非单词边界
\B 非单词边界,不位于单词的开头或者结尾匹配
1 | // \B 非单词边界,不位于单词的开头或者结尾匹配 |
28.7 预定义类
字符集特殊写法
.:除了回车和换行之外的所有字符\w:所有的单词字符字母,数字,下划线_\W:非单词字符\d:数字\D:非数字\s:所有空白字符,比如空格、缩进\S:非空白字符
1 | // . :除了回车和换行之外的所有字符 .+ 表示连续除了回车和换行之外的所有字符 |

28.8 或操作符
| :表示或操作符
1 | // a| b 表示或者是 a 或者是 b |

28.9 分组匹配
() :用于匹配连续多个字符,小括号表示整体
1 | // 匹配 abcabc (abc){2}表示abc这个整体连续出现 2次 |
28.10 分组反向引用
28.10.1 \编码 正则内再次使用
\编码(每一个小括号对应一个编码,不表示次数,从1、2、3、……):
分组匹配到的字符串,可以在正则内部再次使用
1 | // \编码(每一个小括号对应一个编码,不表示次数,从1、2、3、……): |
28.10.2 $编码 正则外再次使用
还可以在正则表达式外部使用。$编码
1 | // "123*456" 改为"456*123" |
replace()第二个参数还可以书写为匿名函数,match函数,可以让操作更加灵活。
1 | // "123*456" 改为"456*123" |
28.11 中文匹配
匹配中文: [\u4e00-\u9fa5]
是一个固定用法,中文只能在正则表达式里这样表示。
1 | // 匹配中文: [\u4e00-\u9fa5] |
